
Updated 27. feb
We have been testing Storage Spaces Direct for a while on our Ebay cluster. We have been running development and some production systems. As the 2nd exchange node, a mediation server and our vmm server.
We have been looking to replace our current Hyper-V solution that consist of HP BL465c G8 and BL490 G7 blade servers attached to HP P2000 G3 MSA over iscsi. This has been slower and slower as we have setup more virtual machines. This was a 12 disk shelf with 11 disks active with one spare. One 15k disk gives about 170 iops, giving a whopping 1870 iops on max speed. On normal load it would use about 1200-1500 IOPS so not a lot of spare IOPS. We had one pr cluster.
Most of you know what S2D(Storage Spaces Direct) is, if you don’t go look at Cosmos Darwin’s post over at Technet to get some good insight about S2D.
What i am going to focus on in this blog is the new Dataon HyperConverged server. Back at Ignite 2016 Dataon released there first offering the S2D-3110 all flash solution pumping out 2.6 Million IOPS in a 1u form factor.
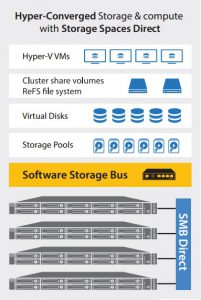
I had known about this solution for a while as i started looking into Dataon in feb 2016, and was informed during the summer about there S2D offerings. For us a all flash system was not needed and we wanted a hybrid solution with NVME for caching, SSD for performance and HDD for capacity. At Ignite i knew that there was a 2u solution on the way, the S2D-3212.

We decided to go for this and made the order in December. We settled on 2 4 node clusters. One for each of our data centers. This is the config we settled on.
4 DataON™ S2D-3212 2U 12-bay 3.5″ Storage Server
Form factor: 2U Rack, 17.6″ (W) x 29.33″ (D) x 3.44″ (H)
Supports Dual Intel Xeon® Processor E5-2600 v4 Series & (24) DDR4 2400 DIMM
Drive Bay: (12) 3.5″ Hot-swappable Front; (2) SATA & (2) NVMe 2.5″ Rear
Total (6) PCIe 3.0 slots: (3) x8 & (1) x16 Available; (2) x8 For Mezzanine
Onboard NIC: (2) Built-In 1GbE RJ45
* (1+1) 1100W High-efficiency redundant hot-plug Power Supplies
* IPMI v2.0 Compliant; “KVM over IP” Support; Native SNMP Support
* TPM 2.0 Kit Included
Compute Node Configuration
8 Intel® Xeon E5-2650v4 2.2 GHz, 12-Core, 30MB Cache, QPI Speed 9.6 GT/s; Dual Processor Per Node
32 Samsung® 32GB DDR4 2400MHz ECC-Register DIMM; 256GB Per Node
4 LSI® 9300-8i PCI-e 3.0 8-port Internal 12G SAS HBA; One Per Node
4 Mellanox® ConnectX-4 EN Dual Port QSFP28 40/56 GbE RDMA Card; MCX414A-BCAT; One Per Node
8 SanDisk® X400 256GB 2.5″ SATA III SSD – Mirrored Boot Drive
Storage Configuration
8 Intel® DC P3700™ NVMe 800GB 2.5″ SSD, Read/Write Cache
Part# SSDPE2MD800G4; Cache Tier; 2 Per Node
16 Intel® DC S3520™ 6G SATA 1.6TB 2.5″ 3D MLC SSD
Part# SSDSC2BB016T7; Performance Tier; 4 Per Node
16 HGST Ultrastar® He8 8TB 3.5″ 7200RPM 12G SAS Nearline Storage Drive
Part# 0F23651; Capacity Tier; 4 Per Node
Fault Tolerance = 2; 17% MIRROR; Multi Resiliency, Efficiency = 46%; Usable Capacity ~63.5TB
(16) Slots Available For Expansion
We also decided to stay with our Dell N4064F switches for now, and upgrade to 40Gbit in the future. (Will come back to this point later.)
We received the servers and the packaging was rely good and i was like wow with the quality and detail on the outside and inside. Here are some pictures from the depacking and racking.
Packaging was rely good.as you can see on the pictures.


The front disk disk trays are 3.5″ but are made of metal that gives you mounting points for 2.5″ drives as well and you don’t need a 2.5″ to 3.5″ adapter.

Once you get into the server you can clearly see the good quality build here

There is plenty of room here for more memory, 1.5 TB in total. If you look on both sides at the rear, on the left there is the 2 OS disks(Hot Swap) that are raided and at the right the 2 NVME 2.5″ Caching devices(Hot Swap)

This the 2.5″ NVME caching devices


And the servers racked. I rely like the blue colors of the disk activity

Configuring the servers is quite straight forward.
The ilo configuration must be done from the bios.
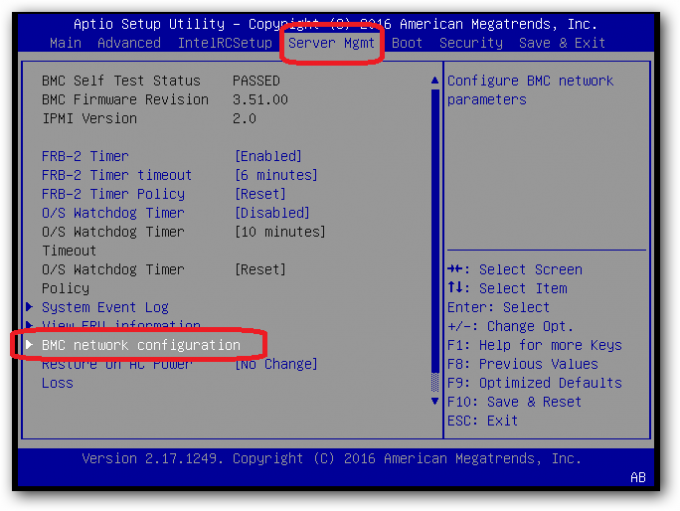
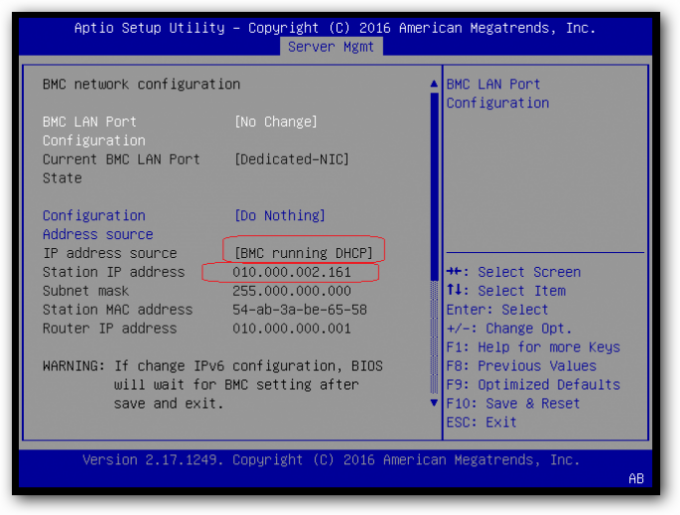
To configure Windows Server 2016 Datacenter for HyperConverged follow Microsoft’s guide at Technet. I also setup with logical switches in VMM that i deployed to the hosts before i setup the cluster. I used the combination of these two guides Charbel Nemnom and TechCoffe. Dataon is also delivering a full script to run, following there guided way of setting the solution up. I used a combination of Technet, Dataon Script, and the logical switch setup for VMM.
For the RDMA setup for the Dell N4064F switches i tried several combination. After going trough all the documentations i got the RDMA to work. But the side affect that i lost communication with all Port-Channels on the switch. That goes to my HP 6120XG blade switches. So had to revert back the DCB settings on the N4064F. It looks to be a spanningtree issue. Will look into this tomorrow with a Consultant from truesec.se. I will come back with update about the DCB setup for N4064F
But the configuration i used was.
conf t dcb enable classofservice traffic-class-group 0 1 classofservice traffic-class-group 1 1 classofservice traffic-class-group 2 1 classofservice traffic-class-group 3 0 classofservice traffic-class-group 4 1 classofservice traffic-class-group 5 1 classofservice traffic-class-group 6 1 traffic-class-group max-bandwidth 50 50 0 traffic-class-group min-bandwidth 50 25 25 traffic-class-group weight 50 50 0 interface range ten 1/0/41,ten1/0/42,ten1/0/43,ten1/0/44,ten1/0/40,ten2/0/41,ten2/0/42,ten2/0/43,ten2/0/44 datacenter-bridging priority-flow-control mode on priority-flow-control priority 3 no-drop
Once i run the priority-flow-control mode on spanningtree starts doing all sorts of things. But all is working fine, once i applied the last line to the interfaces the connections to my blade chassies dropped. There was no new info in the switch console at this point. So why this happens is quite strange.
After setting all up, defining the 4 Virtual Disks for the 4 nodes, one on each node. I did run vmfleet to test the performance. I followed the pdf that is included in vmfleet and this guide.
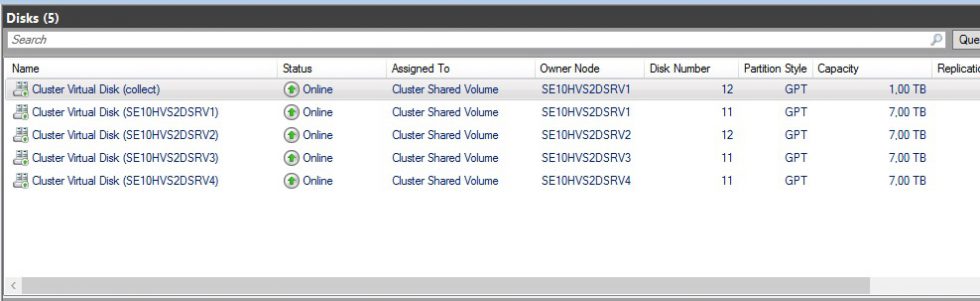
When running vmfleet i used Perfmon to monitor disk activity. Go in and add these counters. And i used watch-cluster.ps1 that isincluded with vmfleet to see overall iops.
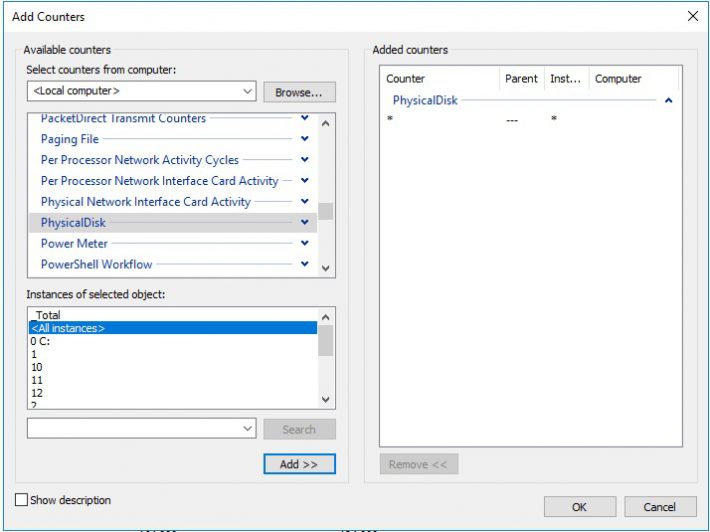
When running vmfleet with 10 vm’s on each host i noticed that one node was not performing at all. So i looked at perfmon i saw something i dread, Avg.Disk sec/read/transfer/write higher then 0.009, they where up to 6.something. When running vmfleet and pretty soon i had IO error when i run Get-PhysicalDisk on powershell on this disk. This means that the storage pool in windows is bypassing the read/write cache on the disk due to no Power Loss Protection. And this is no good, this makes the disk so slow. I managed to get out about 15k iops of that node after letting it run, but it would jump up and down bad.
Here you can see the problem om disk 1 today, i have migrated some VM’s to the other nodes but the parity will move data to it. I retired the disk but this looks to not have any affect.

Spoke with Dataon and they shipped out a new disk with next day delivery which is Monday.
Update.
I recived the disk, replaced it, added it to the pool and rebuild was done in less then 10 minutes. Once the disk was in i had to run
Optimize-Storagepool -Friendlyname S2D
This will rebalance the disk, and fix this little warning.
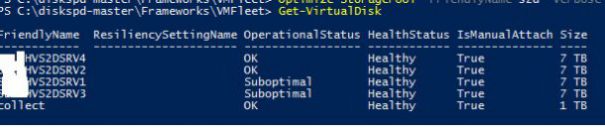
This means it needs a rebalanace.
Back to the ilo, it’s quite nice and simple. The remote ilo for mananging the desktop is quite sweet, it has alot of features and looks quite good. Default login on the ilo is admin admin.



On thursday the 23rd of feb Dataon released Dataon Must, there monitoring solution. And at the same time there was a new pdf with overview 4 hyper converged solutions. And this page

For Dataon Must i will give a write up of Must once i have it installed. I will also update this post later on.

5 thoughts on “Dataon S2D-3212 HyperConverged Cluster”
I am involved in a DataOn deployment right now myself. Can you email me? Thanks.
I thought we might be able to share our experiences with implementing s2d since it isn’t as straightforward as it initially sounds.
Hey
Sorry for not replying. Dod you get this solved? The guys at Dataon is eager to help. What is your problem with the S2D deployment?
I thought we might be able to share our experiences with implementing s2d since it isn’t as straightforward as it initially sounds.
Hey
Sorry for not replying. Dod you get this solved? The guys at Dataon is eager to help. What is your problem with the S2D deployment?