
A week ago i replaced a NVME card on our development Storage Spaces Direct cluster. This did not go as gracefully as i had hoped. Normaly this should work in the following way.
- Pause node and drain the server for all resources
- Shut down server
- Replace NVME card
- Reboot server
- Resume server
This did not go as planned. I ended up with quite alot off issues. This was a late saturday evening. I ended up with disks that looked like this.
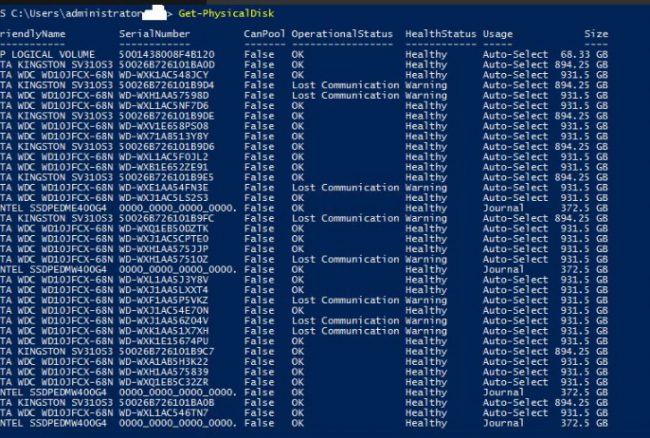
At this point i was worried and posted some twitter msg’s to someone at the MS S2D group that i had talked with before.
The new NVEM card was showing up fine but all the other disks was in a Lost Communication state. I tried replacing all disks and and see if that worked. It did in a way. But the virtualdisk was still degraded.

On monday i got a reply back to contact the S2D group by mail. I gave them all the info needed. And they veryfied that this was a bug. This was fixed in KB3197954 after running this on all nodes and rebooting the rebuild of the server started fine. So make sure you have the latests patches installed before doing anything on your cluster.
Now for some Storage Spaces Direct powershell commands i got from the S2D team id like to share with you all.
If you get the Lost Communication msg on a drive after a reboot or something else and you know it’s working, run this command.
Repair-ClusterS2D -RecoverUnboundDrives
To optimize your storagepool use this command, it will move the data equaly over your disks.
Optimize-StoragePool -FriendlyName 'storagepoolname' -Verbose
To get som stats off your S2D cluster like, IOPS, latency, disk speed and so on, use this little command.
Get-StorageSubsystem clus* | Get-StorageHealthReport
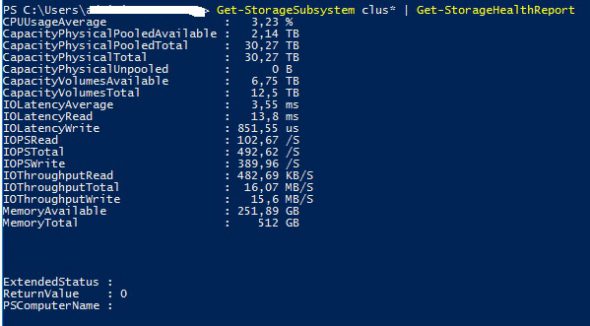
This little bit of commands is for getting out alot of info from your S2D cluster that can be forwarded to the S2D team or for your own browsing 🙂
$Storage = @{
Disk = get-disk
PhysicalDisk = get-physicaldisk
StorageEnclosure = get-storageenclosure
VirtualDisk = get-virtualdisk
StoragePool = get-storagepool
StorageSubSystem = get-storagesubsystem
StorageJob = get-storagejob
StorageTier = get-storagetier
} | Export-Clixml -Path .output.xml
I was given another nice little output script.
$h = @{}
get-storagepool -isprimordial $false | Get-PhysicalDisk | %{$h[$_] = Get-PhysicalExtent -PhysicalDisk $_}
$h | Export-Clixml -Path .extents.xml
I owe a big thanks to the S2D team. You know who you are. Thanks

14 thoughts on “How replacing a NVME card on a S2D cluster caused me alot of hedache”
i have transient error issue at s2d.
could you please take a look at it
here is more detail about my issue :
https://serverfault.com/questions/853065/storage-spaces-direct-windows-server-2016-transient-error
Answered at serverfault.com 🙂
i have transient error issue at s2d.
could you please take a look at it
here is more detail about my issue :
https://serverfault.com/questions/853065/storage-spaces-direct-windows-server-2016-transient-error
Answered at serverfault.com 🙂
it makes me a little dizzy, is there an easier way?
Hehe well this is what i did. 🙂 Let me have a look at it.
it makes me a little dizzy, is there an easier way?
Hehe well this is what i did. 🙂 Let me have a look at it.
So in the end you shut down the node and removed all the NVMe drives, installed new ones and then started the node back up? And that worked with some additional rebuilding.
I am trying to swap out the cache in a 3 Node cluster. Currently there are 4x 1TB SSDs in each node and I have 2x 2TB SSDs to replace them.
If it’s SSD’s you can hotswap you can just put the new drives in. No need to shut down the server. The reason i had to was that the NVME cards was inside the server 🙂
JT
So in the end you shut down the node and removed all the NVMe drives, installed new ones and then started the node back up? And that worked with some additional rebuilding.
I am trying to swap out the cache in a 3 Node cluster. Currently there are 4x 1TB SSDs in each node and I have 2x 2TB SSDs to replace them.
If it’s SSD’s you can hotswap you can just put the new drives in. No need to shut down the server. The reason i had to was that the NVME cards was inside the server 🙂
JT
thanks for information
thanks for information